“검색엔진은 사람과 보는 눈이 다르다”라고 누누히 밝혔지만, 사실 검색엔진은 많은 부분에서 사람들의 의사 결정을 모방하고 있다. "보다 인간스러움”은 모든 AI의 목표다.
특히 이것이 좋은 컨텐츠인가에 대한 검색엔진의 관점은 거의 완벽하게 사람들의 시선과 일치한다. 검색엔진최적화의 테크닉은 이것과 관련되어 있거나, 이것을 검색엔진에게 보다 잘 전달하기 위한 방법들이다.
검색엔진의 입장에서 좋은 컨텐츠란 무엇일까? 특정 키워드를 검색한 사람을 대상으로, 이 컨텐츠를 제공해줬을 때 사용자가 만족하는 것이다. 사용자의 만족도는 단순히 컨텐츠의 품질로 결정될까? 웹사이트의 속도, 모바일에서 버튼과 텍스트의 크기, 정보의 다양성, 관련된 정보의 연관 탐색 등등 수많은 사용자 경험 요소들이 사용자의 만족도에 영향을 미친다. 그래서 검색엔진최적화에서 사이트 로딩 속도, 링크간의 거리, 사진과 동영상 등의 포함여부, 링크 등을 다루는 것이다. 오늘은 이 수많은 검색엔진최적화 요소 중 웹사이트의 구조화를 다루고자 한다.
여기 이순신 장군이라는 동일한 주제를 다루는 두권의 책이 있다. A는 “이순신에 대하여”라는 제목만 있을 뿐, 내용에서는 별도의 챕터 구분이 없다. B는 제목은 동일하지만 아래와 같이 세부 챕터를 갖고 있다.
제목: 이순신에 대하여
1장: 이순신의 유년시절
1절: 이순신의 출생
2절: 어린 이순신
2장: 이순신의 청년기
3장: 과거 급제와 전장에서의 활약
….
6장: 이순신의 눈부신 업적
7장: 이 시대의 우리가 이순신을 돌아봐야 하는 이유
어떤 책이 독자들에게 내용을 잘 전달할까?
사람의 머리는 모든 걸 한번에 담아두고 정리하지 못한다. 정보를 세부 주제에 따라 별도의 수납함에 정리하게 되는데, 당연히 정보의 제공 단계에서 주제가 구분되는 것이 효율적이다.
웹사이트에도 수많은 정보가 있다. 그 모든 정보들이 한 페이지에 모두 들어있는 것이 아니라, 주제에 따라 분류되어 있다. 모든 내용이 한 페이지에 들어 있다면 사용자들이 읽거나 이해하기 힘들 것이고, 이해에 앞서 많은 사용자들이 이탈하게 될 것이다. 이러한 이유로 연관된 주제에 따라 페이지를 구분하여 제작한다. 그리고 그 분류는 메뉴에 잘 반영되어 있다. 하지만 메뉴는 인간 사용자를 위한 것이며, 검색엔진에게 그 분류를 전달하기 위해서는 다른 요소가 필요하다.
일상에서 접하는 구조화의 예
회사의 예를 들어보자
매드타임스/편집부/기자1
매드타임스/편집부/기자2
매드타임스/인사부/직원1
매드타임스/영업부/직원2
조직도가 이렇게 구조화되어 있다면 어떤 직원이 어떤 일을 하는지 파악하기 쉬울 것이며, 어떤 업무를 위해 어떤 직원에게 연락해야 하는지도 쉽게 알 수 있다.
하지만 아래와 같이 조직도가 구성되어 있다면 어떨까?
매드타임스/기자1
매드타임스/기자2
매드타임스/직원1
매드타임스/직원3
또한 조직 내에는 직급도 존재한다.
미팅에 참석했는데 매드타임스의 모든 기자가 “기자”라는 타이틀을 갖고 있다면, 누가 책임자인지 알 수 없게 된다. 구조화에는 단순히 주제별 분류 뿐 아니라, 상하위 서열이 존재해야 한다. 위의 구조화를 직급으로 표현한다면 아래와 같다.
대표이사/편집부장/기자1
대표이사/편집부장/기자2
대표이사/인사부장/직원1
이를 통해 우리는 편집부장이 편집부 기자들 모두와 관련된 일을 하며, 직원1은 인사부장의 업무를 돕는다는 것을 알 수 있다.
검색엔진최적화를 위한 URL의 구조화란?
웹사이트 내 페이지들의 수직/수평 구조를 파악하기 위하여 검색엔진은 URL을 이용한다. URL이 어떻게 구성되어 있는가에 따라 그 페이지가 어떤 주제의 상/하위 페이지이며 어떤 페이지들과 주제를 공유하고 있는지를 파악한다.
일반적인 URL은 아래와 같이 구성된다.
도메인.com/1단계분류/2단계분류/페이지1.html
도메인.com/1단계분류/2단계분류/페이지2.html
검색엔진은 이 URL로부터 특정 페이지가 어느 주제의 카테고리이며, 어느 페이지와 인접한 주제인지 파악한다.
웹사이트의 페이지들 역시 이렇게 구조화되어야 하며, 그 관계는 메뉴 뿐 아니라 URL에 반영되어야 한다.
쉽게 요약하자면, 각 웹페이지의 레벨은 /로 구분되어야 하며, 같은 / 레벨에는 컨텐츠 구조에서 같은 레벨에 속한 페이지가 위치해야 한다.
아래 두개의 URL 구조를 비교해보자.
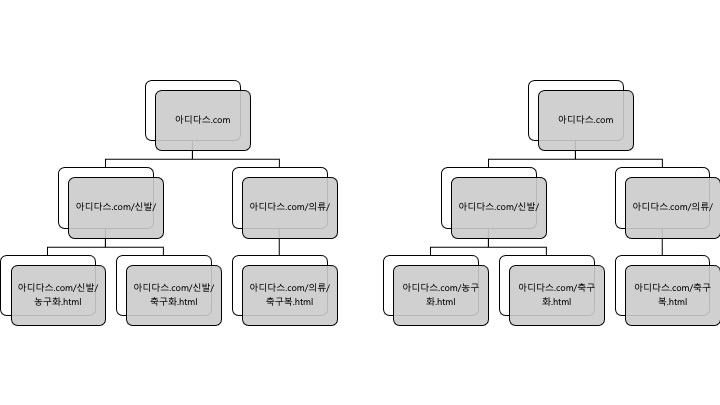
도표의 계층은 웹페이지의 계층이며, 그 안에 URL이 기재되어 있다.
좌측의 URL 구조는 웹페이지의 계층 구조를 반영하고 있다. 신발과 의류라는 카테고리 페이지는 2 Depth, 하위의 제품군 페이지는 3 Depth의 URL 구조를 갖추고 있다.
또한 농구화와 축구화는 신발이라는 카테고리 페이지를 상위에 공유하고 있다.
편의상 제품군을 최하 계층의 페이지로 표현했지만, 개별 제품군 페이지의 경우 아디다스.com/신발/농구화/게임토커.html 이렇게 구성될 것이다.
반면 오른쪽의 URL은 카테고리 페이지와 제품군 페이지 모두 2 Depth의 URL로 구성되어 있다. 이는 웹페이지의 계층 구조와 상이하며, 검색엔진은 최상위 도메인 페이지(메인페이지)를 제외한 모든 페이지가 같은 레벨에서 존재한다고 생각할 것이다.
당연히 좌측의 URL 구조가 검색엔진최적화에서 권장되는 형태다.
마지막으로 마케팅 관련 매체인 매드타임스의 URL을 예로 살펴보자.
Trends 메인: http://www.madtimes.org/news/articleList.html?sc_section_code=S1N37&view_type=sm
Trends-Watch 메인: http://www.madtimes.org/news/articleList.html?sc_sub_section_code=S2N80&view_type=sm
Trends-Watch 기사: http://www.madtimes.org/news/articleView.html?idxno=4139
메뉴에서는 이 네 페이지가 수직 구조를 갖추고 있다. 하지만 URL을 살펴보면, Trends의 메인, Trends 내 세부 주제인 Watch의 메인, 그리고 구조에서 제일 하단에 있는 기사 모두 http://www.madtimes.org/news/articleList.html에서 Depth(“/“로 구분되는 URL의 단위)가 끝나는, 모두 동일한 Depth를 갖고 있다. 단순히 그 뒤에 파라미터로 페이지가 구분될 뿐인데, 파라미터는 URL의 구조를 정의하지 못한다. 직급 구분이 없이 모두 수평 구조로 나열된 것이라 말할 수 있으며, 이 URL 구조는 아래와 같이 개선되어야 한다.
Trends 메인: http://www.madtimes.org/news/trends
Trends-Watch 메인: http://www.madtimes.org/news/trends/watch
Trends-Watch 기사: http://www.madtimes.org/news/trends/watch/기사페이지
마지막으로 한번 더 강조하자면, 검색엔진은 사용자가 탐색하고 이해하기 쉽게 구조화된 웹사이트를 좋아한다. 그리고 그 구조는 URL을 통해 전달되므로 절대로 소흘하게 여겨서는 안된다.
'Search' 카테고리의 다른 글
| 검색엔진최적화에서 구조화의 중요성 - 2. 컨텐츠 | 검색엔진최적화/SEO 강좌] (0) | 2020.03.29 |
|---|---|
| 검색엔진의 눈을 가리는 웹사이트 - 2. 접근성 | 검색엔진최적화/SEO 강좌 (0) | 2020.03.19 |
| 검색엔진의 눈을 가리는 웹사이트 - 1. 컨텐츠 | 검색엔진최적화/SEO 강좌 (0) | 2020.03.08 |
| [검색엔진최적화 | SEO 체크리스트]우리 웹사이트가 검색에 노출되지 않습니다만? (0) | 2020.02.06 |
| "검색엔진최적화된 웹사이트를 팝니다"라니요? (0) | 2019.09.20 |
