지난 글 “검색엔진최적화에서 구조화의 중요성 - 1. URL”을 요약하자면 이렇다.
-
책의 챕터가 잘 구성되어야 독자가 정보를 이해하기 쉽듯, 검색엔진은 페이지들의 구조화가 잘 된 웹사이트가 사용자에게 도움이 된다고 생각한다
-
웹사이트의 구조는 눈에 보이는 메뉴가 아니라 URL의 구조를 통해 정의되고, 검색엔진에게 전달된다
-
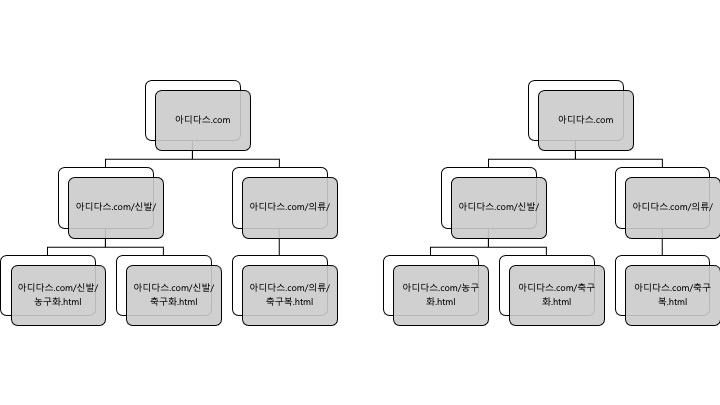
URL 내 각 페이지의 수직, 수평적 관계는 “/“를 이용한 URL Depth에 의해 정의된다
오늘은 컨텐츠 레벨에서의 구조화를 알아보겠다.
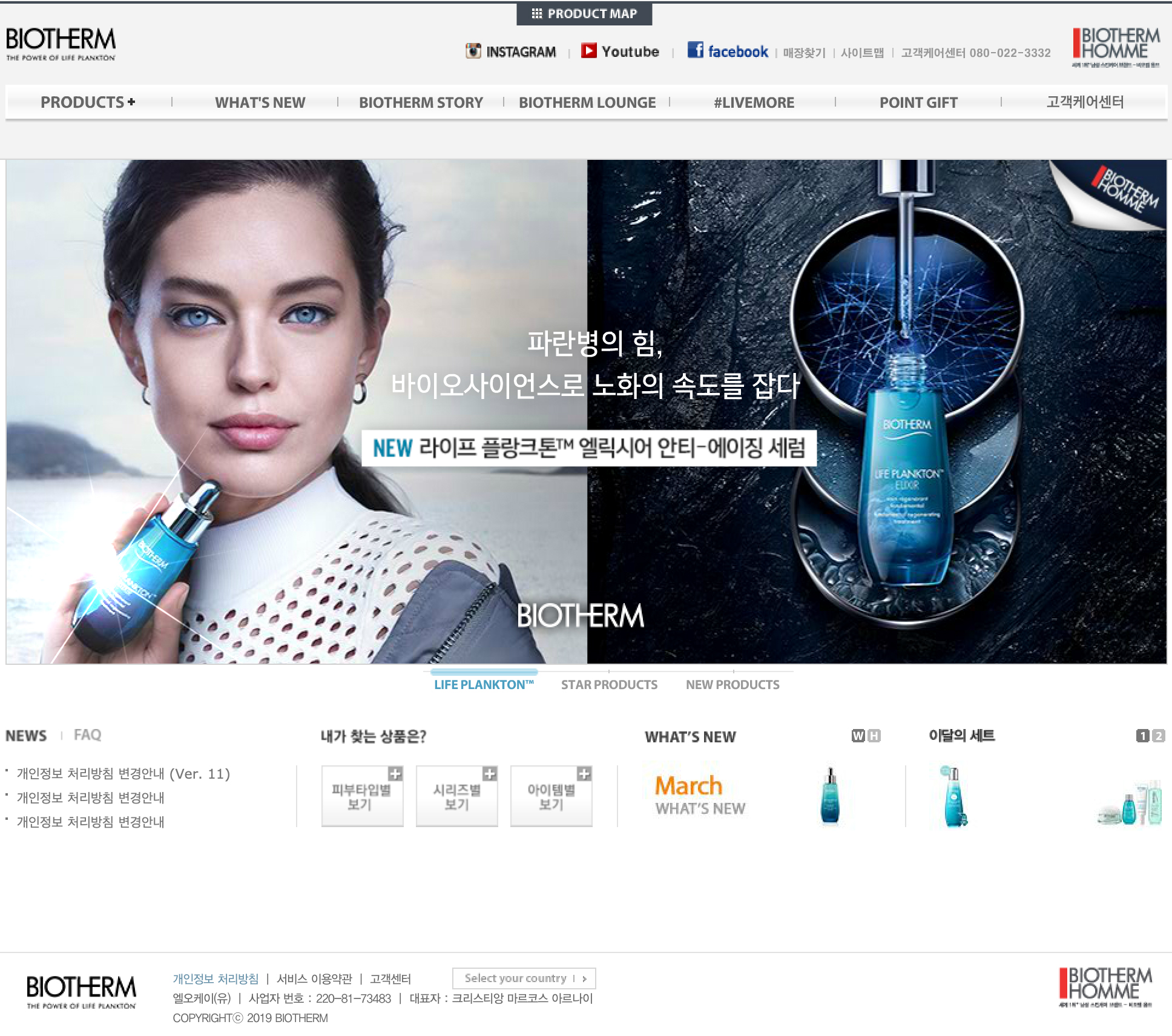
아래의 두 글을 비교해보자.

예시 A는 비록 단락과 문단이 나뉘어 있으나 긴 글이 하나의 호흡으로 이어지는 반면, 예시 B는 같은 내용을 단계적 제목으로 구분하여 전달하고 있다. A와 B 중 어떤 글이 더 정보를 이해하기 쉬울까? 예시에서는 비록 한페이지의 짧은 내용을 다루고 있으나, 이것이 만약 서너배 또는 책 한권의 분량이라면? 당연히 예시 B가 사용자들이 전체 글의 흐름을 이해하고 개별 정보를 머리속에 체계적으로 담아두는데 더 도움이 된다. 그리고 이것은 검색엔진이 컨텐츠의 가치를 평가하는데 있어 가장 기본이 되는 원칙, “이 컨텐츠가 사용자에게 도움이 되는가”와 직결되는 개념이다.
컨텐츠를 구조화하라
컨텐츠의 구조화를 가장 쉽게 이해하고자 한다면 나무위키를 방문하면 된다. 위의 예 역시 나무위키의 정보인데, 나무위키의 컨텐츠는 모두 정보의 내용에 따라 단계적으로 구조화되어 있다.

컨텐츠의 구조화 방법은 검색엔진최적화라고 해서 다르지 않다. 기존에 우리가 알고 있던 “좋은 글쓰기”의 방법을 따르면 된다.
검색엔진최적화된 컨텐츠 구조화
그러나 한가지의 기술적 문제가 있다. 웹사이트의 구조화와 마찬가지로, “검색엔진이 이해할 수 있는 방식”이어야 한다는 것.
우리 눈에 보이는 중제목과 소제목을 아무리 적용해봤자 검색엔진에게는 “독립된 줄(Line)에 있는 짧고 시각적으로 구분되는 텍스트”에 불과하다. 그것이 구조화를 위해 사용된 중제목인지, 주목도를 높이기 위해 사용된 단어 또는 감탄사인지 구분할 수 없다.
컨텐츠의 구조를 검색엔진에게 전달하기 위해서는 Heading Tag라고 불리우는 간단한 태그를 사용한다.
Heading Tag는 컨텐츠의 구조에서 구분 기준이 되는 단어, 문장, 또는 이미지에 적용되는데, H1이 가장 상위 구조이며 H2, H3과 같이 하위 구조로 갈수록 숫자가 커진다.
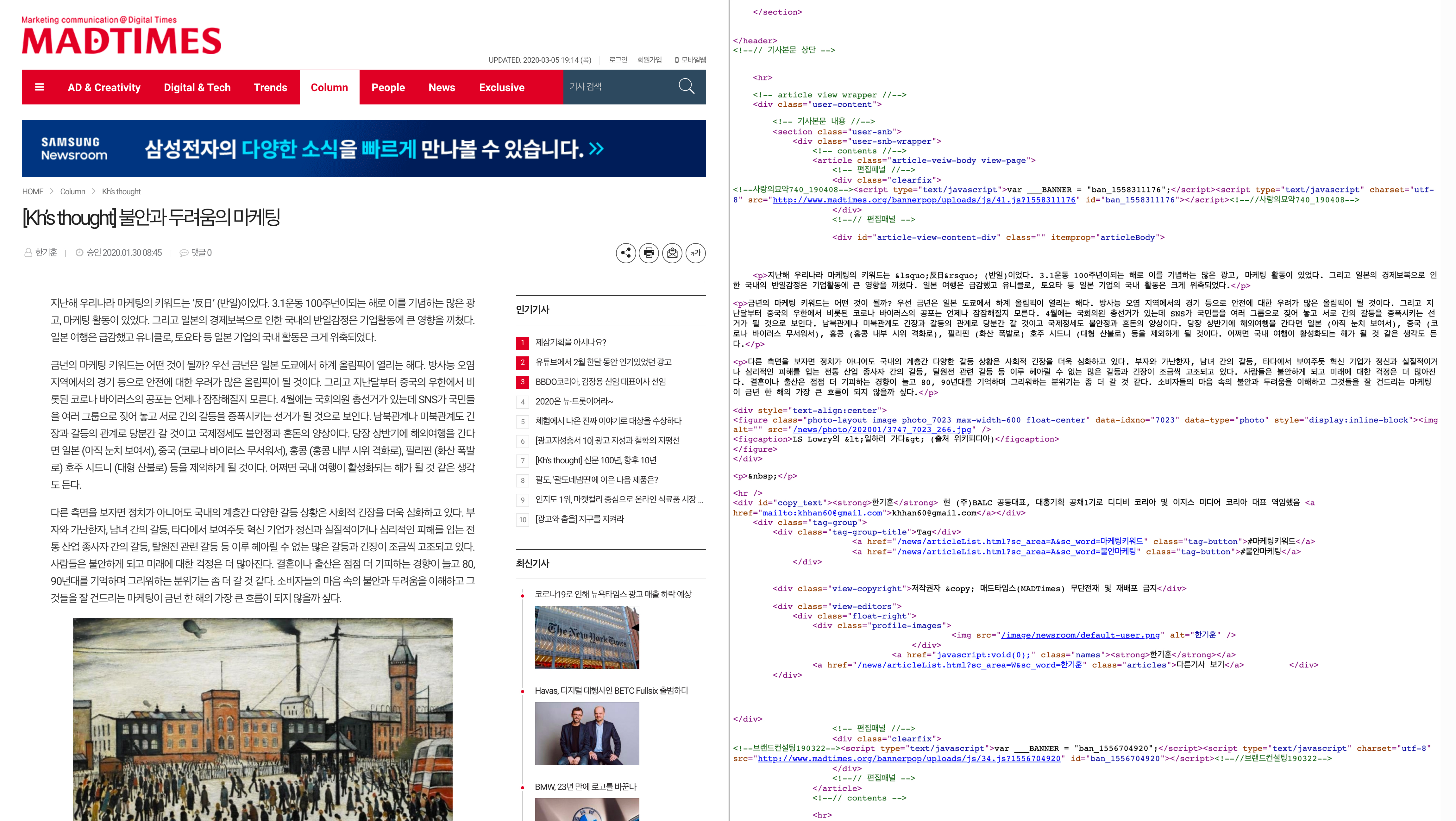
H1은 책의 제목과 같다. 따라서 H1은 한 컨텐츠(웹페이지 또는 블로그 글)에서 하나만 존재해야 한다. 흔히 모든 웹페이지에 공통으로 적용되는 로고에 H1을 적용하는데, 개별 웹페이지의 H1은 해당 페이지의 전체 내용을 다루는 페이지 제목에 적용되어야 한다.
아래의 화면을 보면, 청와대 웹사이트 내 모든 페이지에서 로고가 H1으로 지정되어 있다. 검색엔진최적화의 관점에서 본다면 이 페이지의 내용을 대표하는 “G20 특별 화상 정상회의”라는 제목에 H1이 적용되어야 한다. 물론, 로고를 H1으로 지정한다고 해서 웹사이트의 기능적 문제가 생기는 것은 아니다.

해당 컨텐츠의 구조화를 본격적으로 전달하는 것은 H2 이하의 Heading Tag다. H2 이하의 Heading Tag는 페이지당 1개만 사용되는 H1과 달리 복수로 사용 가능하다. H1이 책의 제목이라면, H2 이하는 장, 절, 그리고 항과 같다. 주의할 점은, 같은 레벨의 컨텐츠는 같은 레벨의 Heading Tag를 적용해야 한다는 것이다. 어떤 중제목이 H2이고, 다른 중제목이 H3가 되어서는 안된다. 모든 중제목에는 H2가 적용되고, H3는 소제목을 위한 자리다.
아래의 페이지를 보자.

실제 이 페이지의 Heading Tag는 이렇게 적용되어 있지 않으나, Heading Tag를 설명하기에 아주 좋은 컨텐츠다.
먼저, 이 페이지의 대표 제목인 “국정과제”가 H1으로 적절하다.
이 페이지는 국민이 주인인 정부, 더불어 잘사는 경제, 내 삶을 책임지는 국가, 고르게 발전하는 지역, 그리고 평화와 번영의 한반도라는 다섯개의 카테고리로 나뉜다. 이 컨텐츠들은 모두 한 페이지 내의 컨텐츠이며, 따라서 이들에게 중제목인 H2를 적용할 수 있다.
H2인 국민이 주인인 정부 컨텐츠는 4개의 전략으로 구분되며, 전략 1 내에는 4개의 세부 과제가 있다. 전략과 과제는 H3과 H4로 지정된다. 과제 1은 목표, 내용, 효과라는 3개의 세부 내용으로 구성되는데, 이들에게는 H5를 적용하면 된다.
Heading Tag를 적용하는 방법은 간단하다. 아래와 같이 소스 내의 지정 영역 앞뒤에 태그를 넣어주면 된다. 영역의 시작 부분에 <h1>을 넣고, 끝부분에는 역시 대괄호 안에 /H1을 넣어주면 된다.

URL과 Heading Tag를 이용하면 웹사이트는 전체적으로 아래와 같은 구조화의 형태를 띄게 된다.

컨텐츠 구조화의 장점
사용자들은 평균적으로 웹페이지 컨텐츠의 20%만을 읽는다. 컨텐츠 방문 후 집중하는 시간은 단지 8초 정도이며, 이는 수초 이내에 사용자에게 “이 컨텐츠는 읽을 가치가 있다”는 것을 전달해야 한다. 구조화된 컨텐츠는 사용자로 하여금 컨텐츠의 전체적인 내용을 빠르게 살펴보고, 보다 흥미를 느끼게 할 것이다. 이를 통해 높아진 사용자의 만족도는 이탈률과 체류시간 등 방문지표 뿐 아니라 소셜 공유와 같은 추가적인 유입경로의 확산에 도움이 된다.
또한, 보다 나은 사용자 경험과 만족도를 제공함으로써 검색엔진으로부터 더 나은 평가를 이끌어낼 수 있다.
'Search' 카테고리의 다른 글
| 검색엔진최적화에서 구조화의 중요성 - 1. URL | 검색엔진최적화/SEO 강좌 (0) | 2020.03.23 |
|---|---|
| 검색엔진의 눈을 가리는 웹사이트 - 2. 접근성 | 검색엔진최적화/SEO 강좌 (0) | 2020.03.19 |
| 검색엔진의 눈을 가리는 웹사이트 - 1. 컨텐츠 | 검색엔진최적화/SEO 강좌 (0) | 2020.03.08 |
| [검색엔진최적화 | SEO 체크리스트]우리 웹사이트가 검색에 노출되지 않습니다만? (0) | 2020.02.06 |
| "검색엔진최적화된 웹사이트를 팝니다"라니요? (0) | 2019.09.20 |